近日,2025年第八届计算机图形和虚拟国际会议(ICCGV 2025)公布论文收录结果,社交平台Soul App研究成果《LLM Gesticulator: Leveraging Large Language Models for Scalable and Controllable Co-Speech Gesture Synthesis》(LLM Gesticulator:利用大语言模型实现可扩展且可控的协同手势合成)入选。

计算机图形和虚拟国际会议聚焦计算机图形学与虚拟现实技术。在人工智能技术实现突破式发展,推动虚拟现实方向进入新阶段的当下,大会关注虚拟现实环境/增强现实/混合现实、人机交互和,交互等领域,计算机图形学与虚拟现实技术的,科研成果和产业发展对人类认知世界、交互体验的深刻影响,也吸引了全球,学者、行业精英及创新先锋,共同探讨技术的进步,携手助力产学研联动。
Soul论文核心亮点为在行业内,提出使用大模型作为基底模型实现虚拟人的多模态驱动,并实现了各项指标超过之前的最佳方案。此次论文入选,也意味着作为致力于以技术和产品模式创新提升年轻一代交互体验的社交平台,Soul的底层技术能力建设和探索方向得到了行业和学界的认可。
事实上,坚持以技术驱动创新,Soul自2016年上线后便注重AI、虚拟人、虚拟与现实融合等方向的技术能力建设。
特别是为了降低用户社交压力,Soul不支持用户上传真实头像,年轻人通过平台提供的捏脸系统,自主创造个性化虚拟形象。
此前,Soul集成AI、渲染和图像处理等技术,推出了自研的NAWA引擎,为用户创建个性化的3D社交形象和场景提供技术支持。2020年,Soul正式启动对AIGC的技术研发工作,系统推进在智能对话、语音技术、3D虚拟人等AIGC关键技术能力研发工作,并推动AI能力在社交场景的快速落地。
目前,Soul已先后上线了自研语言大模型Soul X,以及语音生成大模型、语音识别大模型、语音对话大模型、音乐生成大模型等语音大模型能力。2024年,Soul AI大模型能力整体升级为多模态端到端大模型,支持文字对话、语音通话、多语种、多模态理解、真实拟人等特性,真正实现更接近生活日常的交互对话和“类真人”的情感陪伴体验。
沿着多模态融合的方向,Soul团队希望能够集成3D虚拟人能力创新多模态AI交互方案,为用户提供更加沉浸、自然、流畅、智能的互动体验。相关负责人表示,“3D虚拟人是多模态中的重要组成部分和效果的丰富化呈现,社交则是3D虚拟人落地的最佳自然场景之一,Soul自身具备完整的多模态团队、3D虚拟人/AI能力积累和深耕社交场景的洞察,团队有机会在此领域形成创新方案和竞争壁垒。”
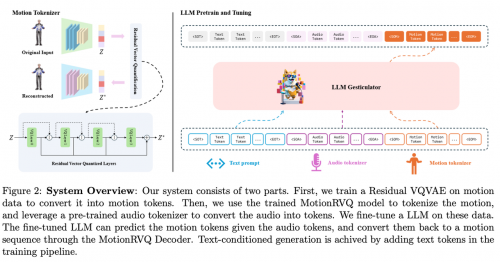
《LLM Gesticulator: Leveraging Large Language Models for Scalable and Controllable Co-Speech Gesture Synthesis》一文中汇聚了Soul在此方向的,研究成果,展现了3D虚拟形象、肢体动作、文字、语言、视觉等多维度真正多模态融合实现的可能性。
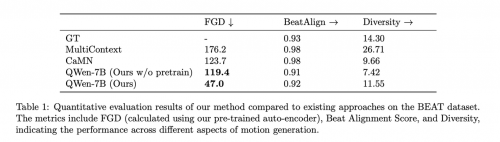
首先,团队,提出使用大语言模型作为基座模型实现3D虚拟人的多模态驱动方案,其展现出了极高的可控性和可拓展性,并且实验表明该模型在动画质量、动画相关性、节奏匹配度和文本匹配度等多个指标上都超过了以往方案。
此外,过往行业方案中大多只支持单一模态的驱动,Soul团队对模型进行了特殊设计,使得模型可以同时支持文本+音频的输入,并能够生成和音频节奏和文本语意都符合的动画数据。
,,团队还探索了一种基于视觉大模型的自动化数据标注范式,提供了新的数据标注思路。
高度重视技术能力建设,2024年Soul多个技术研究成果获得学界和行业肯定。8月,平台研究成果《Multimodal Emotion Recognition with Vision-language prompting and Modality Dropout》(基于视觉语言提示与模态暂退的多模态情感识别),入选ACM国际多媒体会议(ACM MM 2024)上组织的多模态与可靠性情感计算研讨会MRAC 24(Multimodal, Generative and Responsible Affective Computing 2024),该论文,介绍了Soul团队为提高情绪识别的准确性和泛化性能,提出的多模态情绪识别方法。
夯实技术基建的同时,Soul始终强调推动AI能力在社交场景的快速落地,目前Soul大模型能力和创新互动方案已在智能对话机器人“AI苟蛋”、狼人杀Agent、数字分身和,的AI虚拟人智能陪伴功能等场景应用。
在今年10月举办的全球三大IT展之一—— GITEX GLOBAL海湾信息技术博览会上,Soul携集成3D虚拟人能力的多模态AI交互方案亮相,在活动现场,观众可以通过数字装置即时生成3D虚拟数字分身,通过实时动作捕捉与还原,体验自然、流畅、沉浸式的多模态互动。
接下来,Soul集合了3D虚拟人的多模态交互能力将陆续在站内虚拟陪伴、群聊派对、游戏等多个场景落地,让用户通过创新技术的应用在社交中充分展现自身鲜明的个性,精准传递情绪温度,在各种虚实融合的场景中与他人自在交流、互动,感受全新的互动体验。